Web Scraping mit FreshRSS
FreshRSS ist ursprünglich ein RSS Aggregator zum selber hosten. Das Tool ist ziemlich cool – das schon mal vorweg. Aber es hat auch eine noch coolere Funktion: Man kann sich einen RSS-Feed irgendeiner Webseite erstellen, die gar keinen RSS Feed hat oder aber auch von Inhalten einer Webseite, die gar nicht per RSS angeboten werden. Das geht über die Scraping Funktion.
Aber zunächst mal zur Installation
Das ganze läuft auf einem Standardwebhosting. Der einzige Hacken: Man soll laut Anleitung nur den Ordner “p” für das Webhosting freigeben und alle anderen Ordner sollen außerhalb des Doc-Roots liegen. Ich bin bei netcups und da geht das recht einfach. Hier mal mit Beispielpfaden:
- Subdomain erstellen (z.B. fresh.example.com)
- Beim Anlegen der Subdomain das Doc-Root auf
/serverpfad/fresh.example.com/plegen - SSL Zertifikate erstellen
- Dann FreshRSS runterladen und entzippen. Den Inhalt des entzippten Ordners
pper FTP in den Ordnerpim Doc-Root laden. - Alles andere in der ZIP-Datei außer den Ordner
paußerhalb des Doc-Roots per FTP hochladen - Die Rechte des Ordners
datanoch der Gruppe freigeben - Dann open_basedir auf das Websiteroot legen – also nicht das Doc-Root sondern auf das Root des Hostings
- Dann fresh.example.com aufrufen und der Installation folgen
Nun ist FreshRSS ordentlich installiert
Wie geht das mit dem X-Path Scraping?
Das ganze ist hier schon ganz gut erklärt. Aber es fehlen so ein paar Details.
Zuerst fügt man einen Feed hinzu (große blaue Schaltfläche oben links), gibt bei Feed-URL die Webseiten-URL an aber wählt als Art der Feed-Quelle HTML.
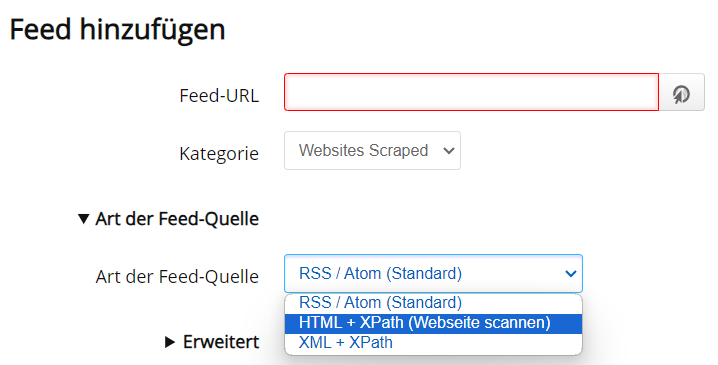
Nun öffnen sich ziemlich viele Optionen. Und man könnte fast aufgeben. Wenn man in der Seite oben nachliest wie es weitergeht, sieht alles recht einfach aus: Im Inspector einer Seite das Wurzelelement wählen, das immer die News enthält und dann klickt man Rechts auf Kopieren -> XPath. Nur kommt da meist ein ziemliches Kauderwelsch raus und nicht so was Schönes wie auf der Seite gezeigt.
Also wie findet man z.B. auf der LfU-Seite immer die neueste Nachricht?
Als Erstes mal JavaScript ausmachen: In Chrome in der Entwickler-Konsole (F12) die Tasten Strg + Shift + P drücken und dann Javascript schreiben und deaktivieren.
Man fängt dann auf der Seite schon im Inspector an aber kopiert nicht blind den Xpath, sondern schaut sich das HTML an und probiert in der Console mit $x("HIER XPATH");
Ich tippe:
$x("//*[@id='hp_aktuelles']//div[contains(@class, 'swiper-slide')][2]//h3[1]")[0];Und wenn ich es richtig gemacht habe kommt nach Enter darunter ein HTML Schnipsel. Wenn ich mit der Maus darüber fahre wird es markiert:
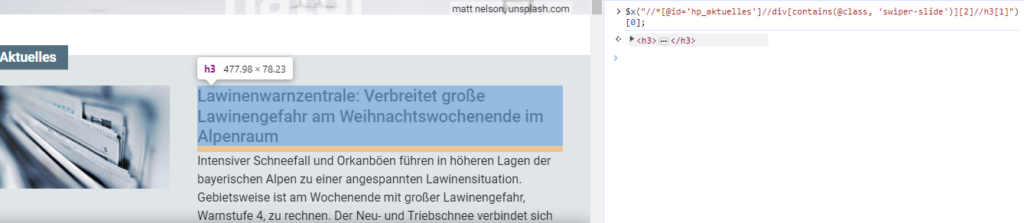
Das sieht ein bisschen komisch aus. Das $x() dient zur Eingabe eines XPath in der Console. Achtung: XPath ist nicht 0-basiert sondern 1-basiert. Ich hole also die erste h3. Aber warum dann am Ende [0]? Das liegt daran, dass die $x() Funktion ein Javascript-Array liefert und ich das erste (in JS 0-basierte) Element haben will.
Soweit so gut ich nehme nun aber den XPath:
//*[@id='hp_aktuelles']//div[contains(@class, 'swiper-slide')][2]das gibt mit den Pfad zum ersten News-Element und füge den bei FreshRSS ein:
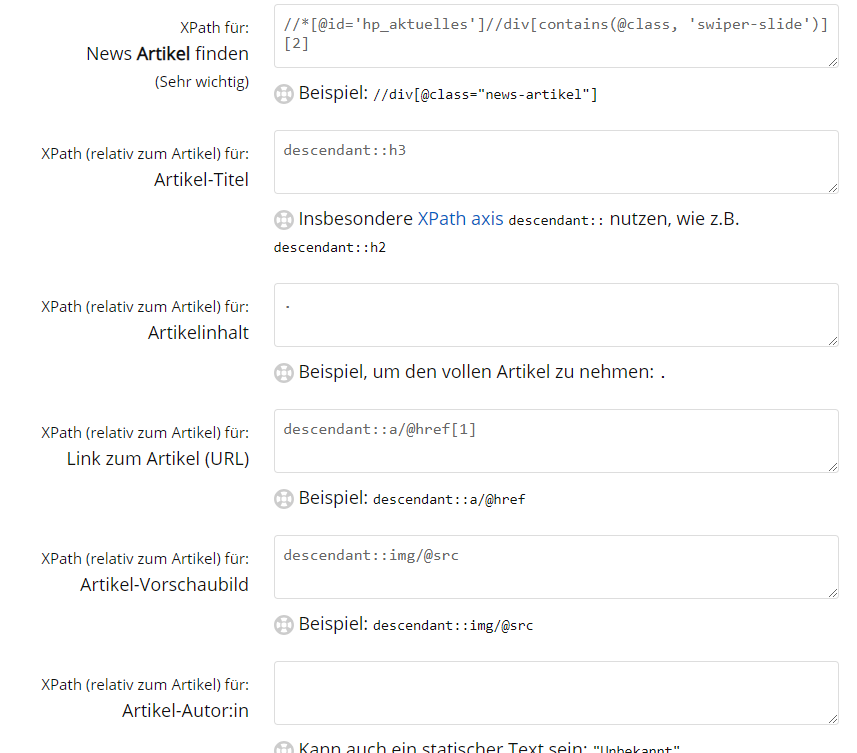
Danach wird es einfach, weil ich nun das Basis-Element für einen Newsbeitrag definiert habe und kann für die anderen XPath Angaben descendant:: nutzen um weitere Elemente darin relativ zu finden. Z.B. Kann ein Beitrag mehrere Links haben und ich wähle mit descendant::a/@href[1] den ersten Link aus, der dann mit dem Titel verknüpft wird.
Zum Schluss bitte im Browser nicht vergessen JavaScript wieder an zu machen 🙂
Was kann ich noch in FreshRSS nutzen?
Man kann übrigens einfach die Adresse eines Bluesky-Profils als neue Feed-URL eingeben.
Oder auch eine Mastodon Adresse mit .rss dahinter: https://mastodon.social/@ulrischa.rss
Oder man kann ein Github Repository überwachen: https://github.com/FreshRSS/FreshRSS/releases.atom
Als erster einen Kommentar schreiben.
Schreibe einen Kommentar